Исследователи МФТИ совместно с коллегами из Института AIRI и Университета Иннополис разработали метод, который позволяет большим языковым моделям отвечать на сложные вопросы о происходящем на видео, отслеживая движения объектов и их взаимодействие. Технология прежде всего нужна для «умных» роботов, работающих в меняющейся среде — например, в логистике, на производстве или в бытовом сервисе. Исследование опубликовано в научном журнале Technologies.
Традиционные системы компьютерного зрения хорошо распознают статичные объекты на картинке, но испытывают трудности, когда нужно понять динамику: кто за кем взял предмет, с какой последовательностью происходили действия или что произойдёт дальше. Кроме того, при попытке описать длинное видео текстом современные языковые модели либо «забывают» начало, либо начинают выдумывать детали.
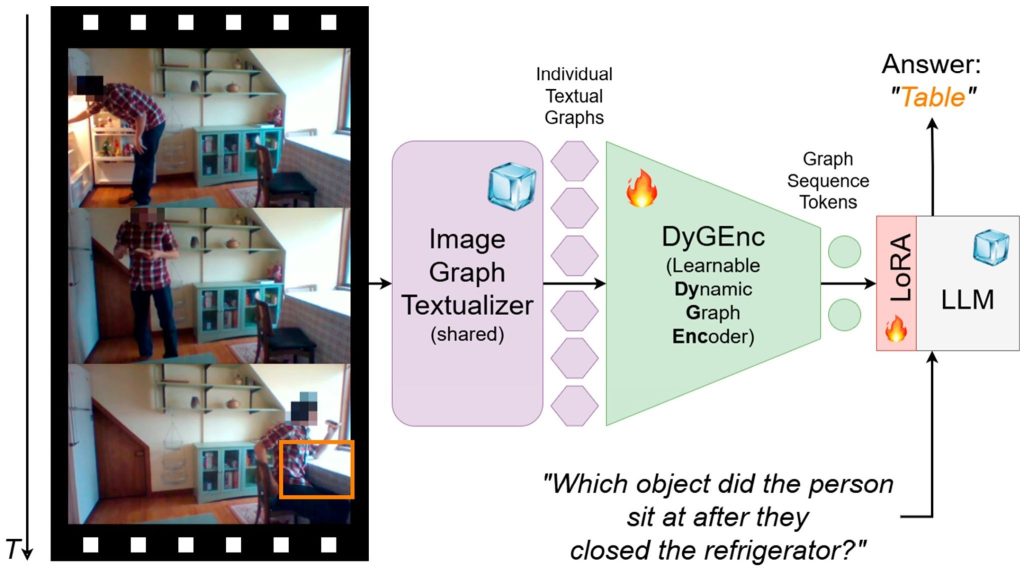
«Мы предложили метод, который назвали DyGEnc. Он сжимает происходящее на видео в специальную структуру — граф событий, где каждый объект-вершина связан с другими объектами и предметами с помощью ребер-действий. Затем эта структура кодируется и подается в языковую модель, которая уже отвечает на вопросы. Получается, что общая картина как бы собирается из отдельных кусочков», — пояснил соавтор разработки, заведующий лабораторией интеллектуального транспорта МФТИ-НКБ ВС Дмитрий Юдин.
Эффективность метода проверили на международных бенчмарках — базах данных, которые используются для сравнения разных систем ИИ.
На тестах с известной графовой разметкой STAR (9 тысяч видеороликов с бытовыми сценами) разработанный алгоритм правильно ответил на 99% вопросов о том, как объекты взаимодействуют друг с другом, и на 97% — при прогнозировании того, какое действие будет следующим. Более сложные испытания на базе AGQA, где требовалось ответить на 2,27 млн вопросов разного типа, показали, что после дообучения нейросеть понимает открытые вопросы (требующие развёрнутого ответа) с точностью 93%, тогда как без использования нового метода этот показатель составлял лишь 54%.
Разработчики испытали алгоритм на реальном роботе — мобильной платформе с рукой-манипулятором. Робот успешно получал задания на русском языке — например, «подъехать к столу и взять предмет» — и выполнял их, анализируя видео с камер в реальном времени. Для этого видеопоток сначала преобразовывался в текстовое описание действий с помощью вспомогательной нейросети с визуальным входом, а затем обрабатывался методом DyGEnc. Эксперименты показали: система справляется даже при наличии шумов и неточностей в описании сцены.
«Наш метод сохраняет высокую точность даже при ошибках в описании видео. Чтобы убедиться в этом, мы специально добавляли шумы во входные данные – удаляли до трети связей между объектами или заменяли слова синонимами. Даже в таких условиях точность ответов оставалась выше 90%. Это особенно важно для практического применения, когда идеальное описания окружающей обстановки получить затруднительно. Следующим шагом может быть исследование единой нейросетевой архитектуры, которая на вход сразу принимает видео, без явного промежуточного шага для получения графовой текстовой разметки», — добавил основной автор метода, разработавший его в рамках кандидатской диссертации в лаборатории интеллектуального транспорта Центра когнитивного моделирования МФТИ, Сергей Линок.
Исходный код опубликован в открытом доступе на GitHub, чтобы другие научные группы могли использовать его в своих проектах.